A proof of concept, in three prompts
Periscope
Lens, K9s and Rancher give you a polished window onto a Kubernetes cluster — the control plane's manifests laid out, related and drillable. Periscope is the same idea, as a Vantage proof of concept: the cluster as browsable, related tables — put together with almost no effort.
What's worth telling is how. Periscope is a Vantage example app that an AI agent — Claude Opus 4.8 — wrote in three prompts: one for the data source, one for the integration, one for the app. Here is each, and everything it pulled in.
Prompt one
The missing data source: the Kubernetes API
Vantage already speaks REST — its api-client data source turns endpoints
into tables — so the obvious move is to point it at the Kubernetes API. It
doesn't fit. Kubernetes doesn't hand back flat rows; it returns deeply
nested objects, with numbers hidden inside strings like
"16331752Ki". And its relationships aren't foreign keys: a pod
belongs to its ReplicaSet by an owner-reference id, a Service finds its pods
by matching labels, everything is grouped by namespace. A generic REST
client that drills through a plain references: foreign_key can't
follow any of that.
So Periscope needed a real, native data source — and adding one is a path Vantage documents, the same path whether you're teaching it SQL, a REST API, a document store or a cluster. It's how Vantage UI gets something to drive. The guide runs to nine steps, and you stop when your source has enough; watch each step the agent built slide up into the prompt that asked for it.
use new persistence guide to add one for kubernetes, stop when done
Every store has its own idea of types — SQLite has five storage classes, Postgres has dozens, SurrealDB its own. So before anything else Vantage needs a type layer that remembers what each value really is, rather than letting a string quietly turn into a number somewhere downstream. You declare it with a single macro:
vantage_type_system! {
type_trait: KubeType,
value_type: serde_json::Value,
type_variants: [Null, Bool, Integer, Number, Quantity, Text, Time],
}For Kubernetes it pays off at once: a Quantity knows that
"16331752Ki" is sixteen gigabytes and "250m" a
quarter of a CPU — real numbers you can sort and chart, not text.
If a backend runs queries, Vantage needs a way to build them: a small
vendor macro that produces a typed expression with safely-bound
parameters — sqlite_expr! for SQLite, surreal_expr!
for SurrealDB.
let q = sqlite_expr!("SELECT * FROM product WHERE price > {}", 100i64);Not needed for Kubernetes — the API has no query language to build against, so the agent skipped it and filters the fetched list instead.
So nobody hand-writes expressions, this layers ergonomic methods onto
typed columns — .eq(), .gt(), .in_()
— each producing the backend's native condition.
table.add_condition(price.gt(100)); // → WHERE price > 100Not needed for Kubernetes — with no query to push a condition into, there is nothing for these to build. Skipped.
The piece that assembles fields, conditions, ordering and limits into a statement and runs it through one standard interface, so every backend builds queries the same way. (MongoDB skips it too, using native pipelines instead.)
SqliteSelect::new()
.with_source("product")
.with_condition(price.gt(100))
.with_limit(20);Not needed for Kubernetes — a resource list comes back whole and is filtered in memory. Three steps the guide lets you walk straight past.
This is the heart of it, and it's a clean bargain. You — or your agent
— implement a single trait, TableSource: the one piece that
knows how to talk to your backend. In return Vantage hands you everything
layered on top, none of which you write — a typed
Table<DB, Entity>, an ActiveRecord-style record you can
load and edit, readable and writable data sets, CRUD, aggregates,
ordering and pagination.
// You implement one trait — the only backend-specific code:
impl TableSource for KubernetesCluster { /* list, read, … */ }
// In return, every backend gets the same toolkit, for free:
// Table<DB, Entity> · ActiveEntitySet (ActiveRecord) · ReadableDataSet
// WritableDataSet · aggregates · ordering · paginationFor Kubernetes the only backend-specific work is the read path: a small projector that flattens each nested object into a flat row and pulls out the fields people actually read.
// one pod's nested JSON → a flat, typed row
row.set("namespace", &pod.metadata.namespace);
row.set("node", &pod.spec.node_name);
row.set("ready", ready_ratio(&pod.status)); // "2/3"
row.set("restarts", total_restarts(&pod.status)); // 7That's all it takes for pods and nodes to behave exactly like database
rows — the same Table and record API the rest of Vantage
already speaks.
This step enables Vantage's relationship engine: you declare how
records relate — with_one for a belongs-to,
with_many for a has-many — and from there the UI picks them
up on its own, turning every reference into a link you can follow, with
no per-screen wiring.
Table::new("replicasets", cluster)
.with_many("pods", "owner_uid", Pod::table); // a ReplicaSet → the pods it ownsHow much a relation can do depends on the backend. SQL is the
most powerful: because the database evaluates them, relations
there carry expressions and aggregation — a client's
order_count, the sum of an order's lines — computed as
correlated subqueries on read.
.with_many("orders", "client_id", Order::table)
.with_expression("order_count", |c| {
c.get_subquery_as::<Order>("orders")?.get_count_query()
})Simpler sources keep the relation, just not the cleverness. When a backend can't narrow results after a traversal, Vantage applies those conditions client-side, so the link still resolves to exactly the right rows. For a REST API the conditions are instead sent the way each endpoint expects — folded into the path or the query string.
For Kubernetes that means owner-reference ids and label selectors, matched against the list Vantage already holds — which is what lets a namespace open into its workloads, and a deployment reach down through its replicasets to its pods.
A table can be defined two ways in Vantage, and both are first-class:
as a typed model in Rust, or declaratively in YAML with Rhai for the
computed fields. Rust gives you compile-time types and the full expression
API; YAML lets you add or reshape a table without recompiling — the next
step is what makes that possible. For vantage-kubernetes the
agent wrote the models in Rust, since the projection is code anyway — a
few lines per resource kind:
Table::new("pods", cluster)
.with_id_column("id")
.with_column_of::<String>("namespace")
.with_column_of::<String>("node_name")
.with_column_of::<String>("ready")
.with_many("metrics", "pod", PodMetrics::table);A dozen of these later — pods through jobs, plus live metrics — the backend type is erased, so the same generic UI, CLI and API code runs over any model, Kubernetes or otherwise. The agent proved the seam by drilling a live cluster from a small CLI:
$ k8s-cli apps.deployment name=web :pods
web-8fc56b787-9hgtz demo Running 1/1
web-8fc56b787-cgmkf demo Running 1/1
web-8fc56b787-zgjcp demo Running 1/1
# → exactly the three pods it ownsEverything so far is perfect for Rust code — and invisible to everything else. Vista is the bridge: it wraps a typed table as a schema-bearing handle that the UI, scripts and agents read over a plain serialization boundary, and it can load straight from a YAML schema so nothing on the other side needs a Rust struct. It's the same doorway for every backend, and it's exactly what gives Vantage UI something to drive — the next two prompts build entirely on it.
One last touch the same Vista boundary unlocks: small expressions in Rhai, evaluated at runtime, so a computed column or a label can be written and changed in YAML without recompiling — a ready ratio here, an age there. The data source isn't just readable; it's scriptable.
- { name: ready, value: "${ record.ready }" } # "2/3", via a Rhai helperall_inclusiveEvery step above, from one sentence. The agent stopped there — Kubernetes is read-only, so the guide's remaining steps didn't apply — and out came vantage-kubernetes: a new crate, +5,915 lines, 8 library and 9 integration tests green.
Prompt two
Vantage learns to speak it
A crate on its own is just a library. The second prompt wired it into
Vantage as a first-class data source kind — mirroring the
existing AWS loader, so any YAML app can say type: kubernetes
and point at a cluster. Four pieces, again pulled into one ask:
register the new vantage-kubernetes crate as a Vantage data source
A new data-source kind. First, Vantage
learns that kubernetes is a thing you can connect to —
type: kubernetes, with an optional context and
namespace — so a YAML app can name it like any other source.
A per-table query loader. Then the piece that turns each table's YAML columns into a live query surface against the cluster — built to mirror the existing AWS loader, so it slots into machinery the rest of Vantage already understands.
Connection plumbing. The connection is threaded through the app's open, resolver and entity paths, loading your current kubeconfig context or, in-cluster, the pod's service account — the unglamorous wiring that makes "connect" actually connect.
Surfaced in the UI. Finally the new kind shows up in the Add data source dialog, so it's a first-class choice and not a hidden config flag.
deployed_code_updateThreaded through the whole app in one prompt — and shipped as Vantage 0.20.
type: kubernetes
context: minikube # optional — defaults to the current kubeconfig context
namespace: demo # optional — the namespace pages open inkubernetes now appears in the Add data source dialog.This integration lives in the private Vantage UI repository, and the published builds don't yet ship the Kubernetes backend — so Periscope won't open in a stock download just yet.
If you want to point Vantage at your own cluster and try Periscope for real, I'm happy to make you a custom build — open an issue and say hello.
Prompt three
The control room, in YAML
With a datasource Vantage understands, the third prompt built the app itself — described in a sentence, delivered as YAML. Here's the whole control room being pulled into the ask:
build a Lens-style Kubernetes browser on the kubernetes datasource
Twelve resource tables. Nodes, namespaces, pods, deployments, replicasets, services, configmaps, secrets, jobs and events — plus live node and pod metrics — each a short YAML file naming the columns worth showing.
Relations both ways. A references:
block declares the drill-downs (namespace → workloads → pods, node →
pods), and the same machinery lets a namespace or node cell drill back
up — the traversal Prompt 1 built, now spent.
Two dashboards. An overview
of capacity, replicas and restarts, and a usage board of
live CPU and memory — each with a Namespace control that re-scopes the
namespaced charts.
Three Summary views. Bespoke node, deployment and pod panels — badges, progress bars, stats and relation lists — so a selected row reads like a briefing, not a raw record.
Both layouts. binder pages
that auto-generate relation tabs alongside the Summary, and
burger explorers for vertical drill-downs — two different
ways to move through the same graph.
A grouped sidebar and a theme. The navigation grouped into sections, and a Tokyo Night / Ayu Light theme — the finish that makes 32 YAML files feel like an app.
all_inclusiveAll of it as 32 YAML files — and zero lines of UI code.
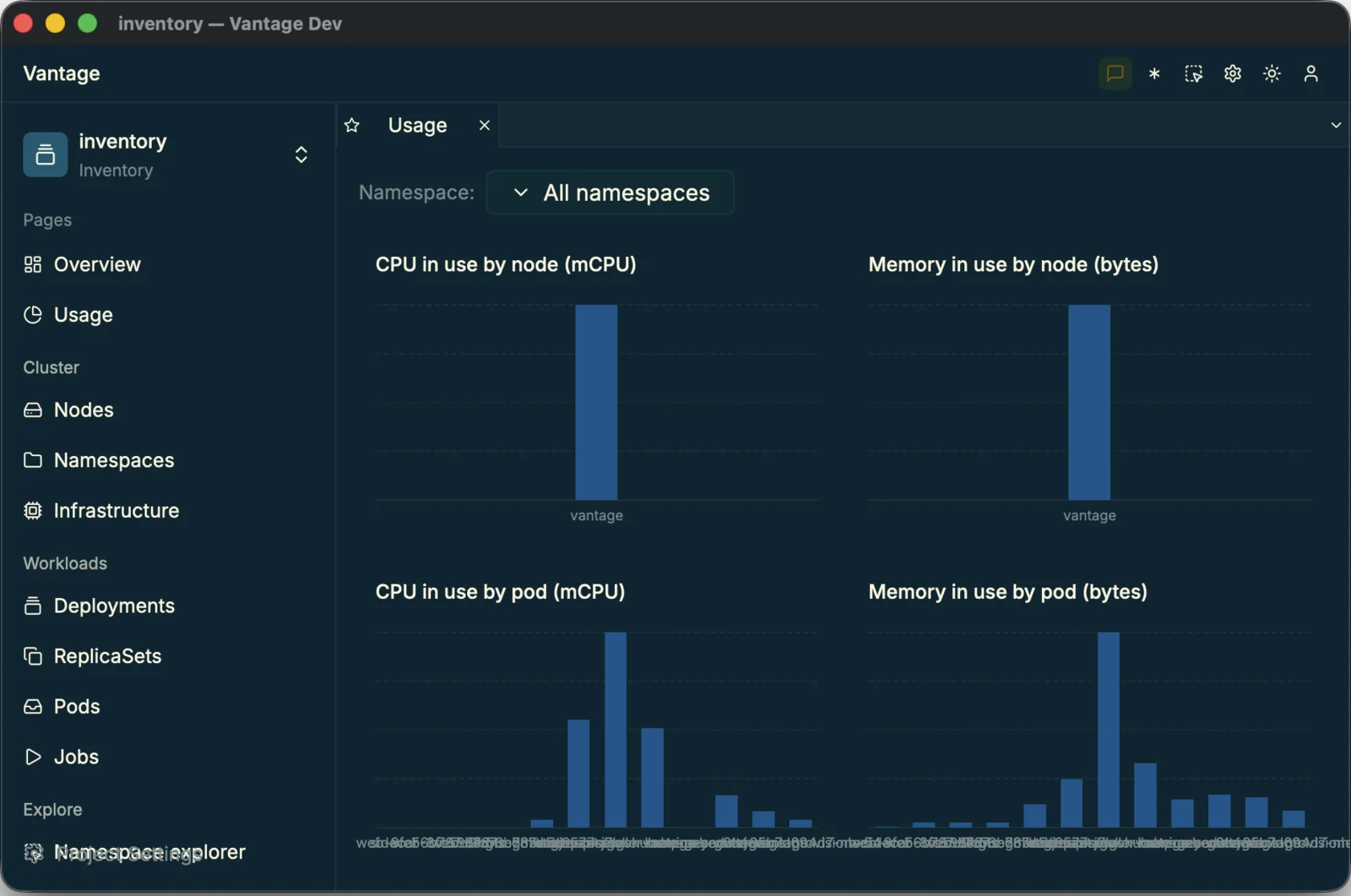
usage dashboard — live CPU/memory, with a Namespace control that re-scopes the namespaced charts.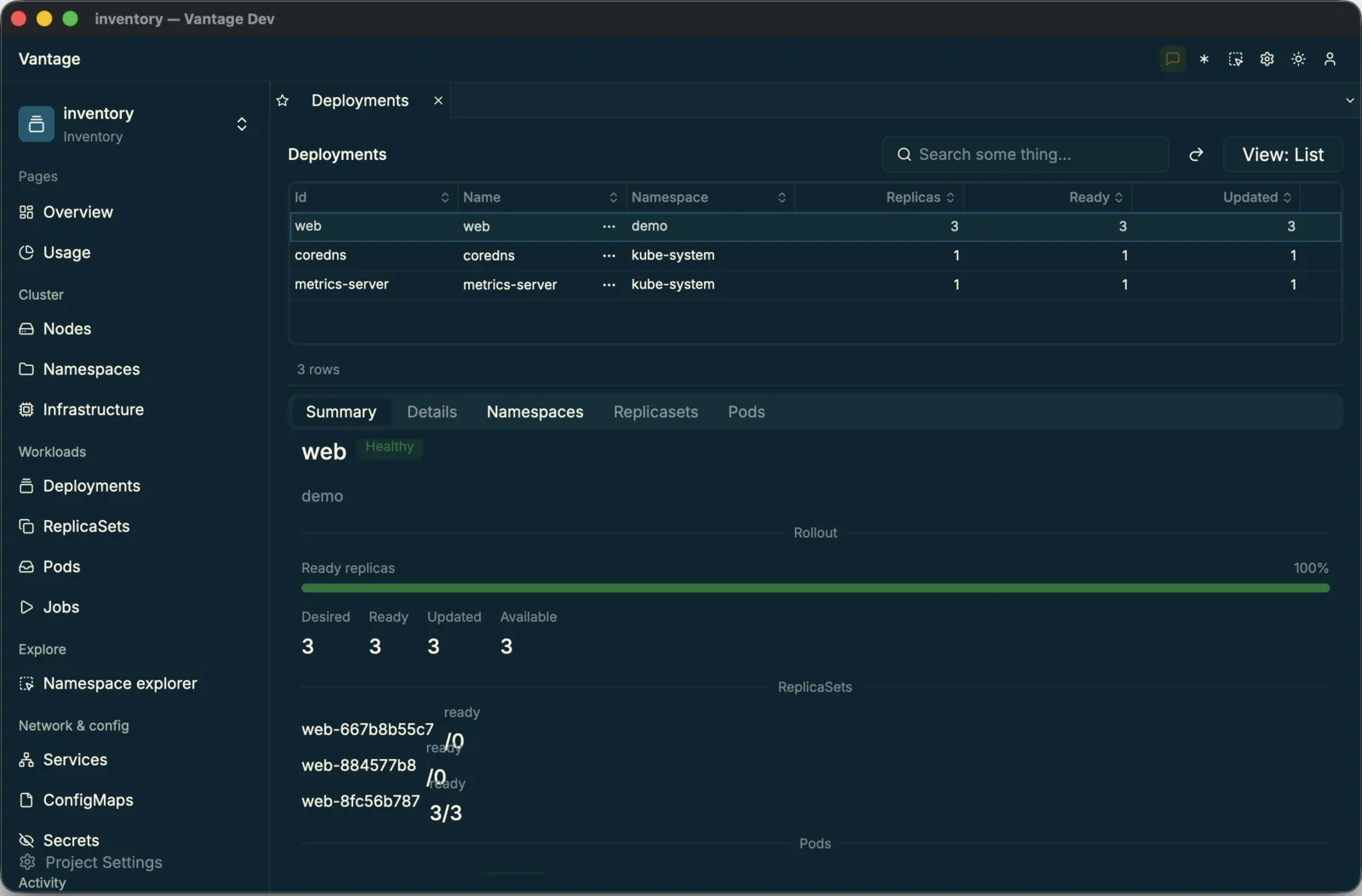
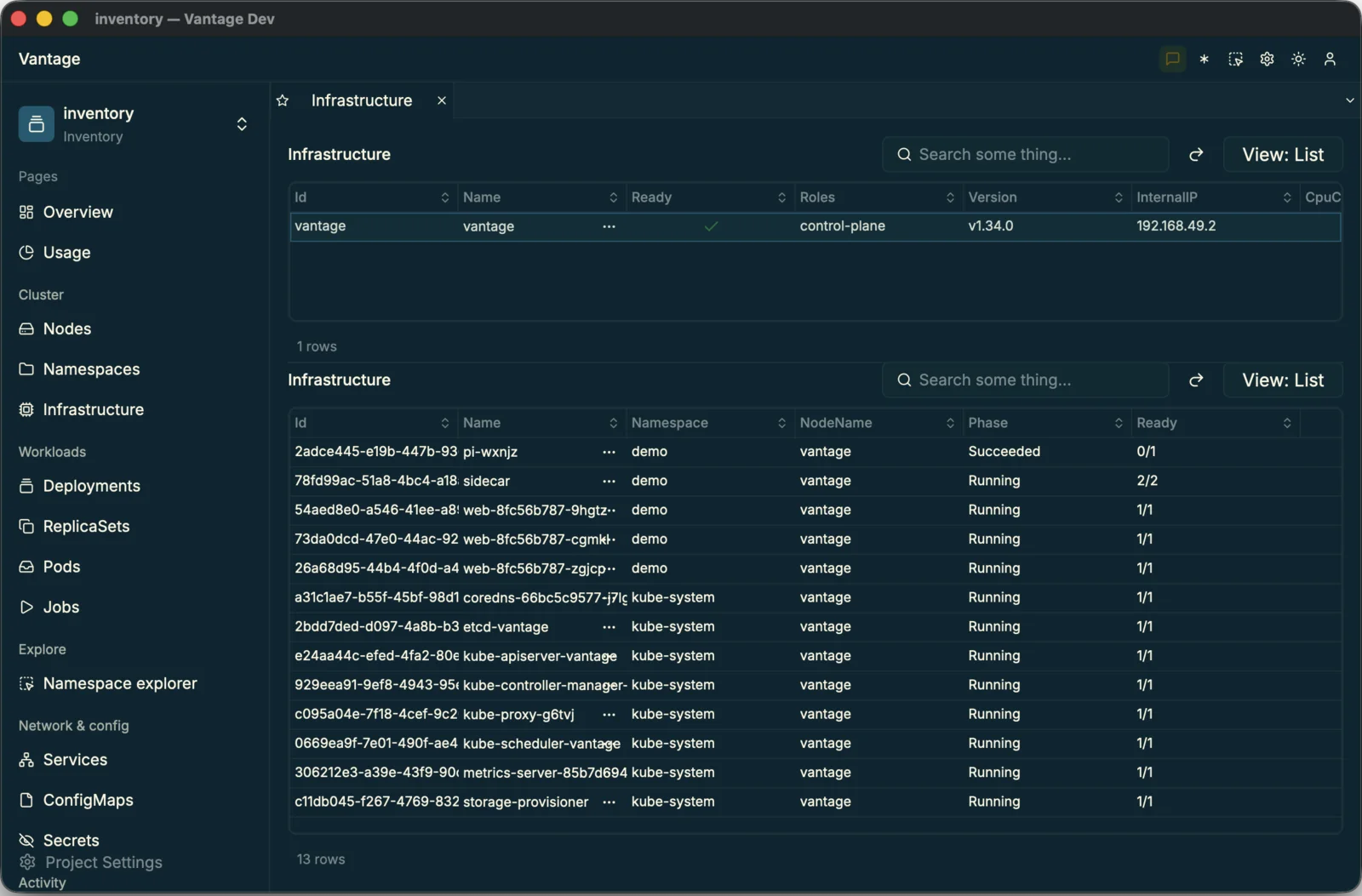
connected kubernetes cluster datasource=cluster,
dashboards bound to live node data.
Read PR #17.
The result
The treasure at the bottom
There's no chest down here. The treasure at the bottom of the dive is what
three prompts produced: a native Kubernetes datasource, a UI that speaks it,
and a full control room over a real cluster — zero lines of UI
code, no kubectl, written and tested in an afternoon
instead of a quarter. The prize was never the app. It's the speed.
And it generalizes. Because Vantage is AI-ready end to end, you can point an agent at its guides and turn any backend — an API, a database, a CLI — into a drillable, related-table app. Periscope is what that looks like when the backend is a cluster. Yours could be anything you operate.
Surface with it
Read the source, follow the three prompts that built it, or ask for a custom build to drive your own cluster.